

Hey guys,
welcome back to my blog and welcome to my first #deepdive blog post. Unfortunately, it’s been a bit quiet the last few weeks, but that’s about to change. In today’s blog post, we’ll take a look at the Pluggable Storage Architecture (PSA) and what it can do.
I had the inspiration for this post a few months ago. In a troubleshooting session, I reviewed the vmkernel.log and looked for an error. During the troubleshooting, I kept noticing three letters – NMP. I was a bit curious what these letters were all about and started reading the VMware documentation. I quickly came across the term “Native Multipathing” and began to understand exactly what it meant. At some point in my learning sessions through the documentation I came across the PSA and how it is responsible for shoveling IO off the ESXer to its storage. I found this so interesting that I would like to write a blog post about it and tell you more about this little piece of software.
Foreword and what knowledge do I need for the following article?
Essentially, the article is primarily intended to gain knowledge. However, it does not hurt if you have a rough understanding of multipathing. You should also know what a path is and what storage cluster variations there are (active/active, active/passive, asymmetric (ALUA)).
I would also like to thank my colleague Alex who helped correct the article for technical errors. Feel free to visit Alex on LinkedIn or his blog. There are few technicians who have so much experience in the field of storage and VMware. 🙂
What is multipathing and why do we do it?
In order to understand what the PSA is responsible for, a brief refresher on multipathing is required. For the sake of simplicity, I will only refer to an ESXer in the following context. This makes writing a little easier.
In order to avoid single-point-of-failures (so-called SPOFs), physical servers usually have redundant designs. The connection of the cables (from the storage/network) to the physical end devices (ESXers) plays an important role in creating a design that is avaialbe as much as possible. It therefore makes sense to avoid SPOFs and to cable servers redundantly. There are now several ways to reach our destination (e.g. LUN). These routes are called paths. Paths can now be active, can serve as standby or can even be dead. For this reason, we will see several paths among our storage adapters (e.g. FC-HBAs). Multipathing is not only used to avoid SPOFs. It can also be used for load balancing. We will look at this again later.
So what is Plugable Storage Architecture (PSA) and what is its purpose?
Essentially, we can answer this question relatively easily. The PSA is a framework within the VMKernel. This framework manages various plugins that ultimately allow multipathing operations. The tasks of the PSA can be concretized as follows:
- the PSA ensures that new paths are used or dead paths are marked as dead. It determines how new or dead paths are handled.
- The PSA provides an API to build your own plugins. We call these plugins multipathing plugins.
So what exactly is the task of multipathing plugins?
The standard multipathing plugin for block storage is native multipathing (NMP for short).The high-performance plugin (HPP for short) is responsible for local, NVMe and vSAN storage. These plugins are supported by all storage manufacturers that are on VMware’s HCL.
Summarized in a few sentences, the multipathing plugins of the PSA ensure that the physical paths are mapped to the correct storage devices and that the IO arrives where it is supposed to arrive. This can be a LUN or a disk in the context of vSAN. Or in other words: the IO should ultimately run via the correct paths. Other tasks include recognizing path failovers to another path, registering and deregistering logical devices such as LUNs or pushing IO over the paths is one of the tasks of the plugins. If you would like to read about other tasks, you can find a complete list here.
Within NMP and HPP there are further plugins which we will look at later.
How do the plugins differ (NMP vs. HPP)?
As mentioned above, there are two types of standard plugins. The first plugin is the NMP. This has been around since ESX 4.0 – long before my time. Accordingly, it is a bit “outdated”, but still fulfills its purpose.
Fast disks have been on the rise in recent years and NVMe’s have become more widespread and more used. High Performance Plugin has therefore been available since version 6.7. This is the successor to NMP and is designed for significantly more modern and faster disks, such as NVMes. The HPP is the default plugin for NVMe over Fibre Channel as well as NVMeoFabric and thus bypasses the SCSI overhead, which in turn ensures better performance.
The NMP is still available, for example for HDDs. The HPP should never be used for slow storage. The good thing is that your ESXi decides independently which plugin to choose.
The Storage Array Type Plugin (SATP) is responsible for managing paths between the ESXi and the storage array. It recognizes new paths, removes inactive paths and controls the automatic failover in the event of problems with the storage. SATP also recognizes whether the storage array
- fixed: The IO always takes the same available path. If this is not available, it switches to another path. If that path is available again, it switches back to the original path.
- MRU (Most recently used): The last functioning and used path is used. There’s no switchover after a failure.
- RR (Round Robin): IO is distributed evenly across all paths. This provides the best possible load distribution. This PSP is recommended by VMware for NMP.
HPP has been available in addition to NMP since version 6.7. This brings a new scheme for path selection (PSS) which is no longer comparable with the PSP under NMP.
HPP has a dynamic path selection, which ultimately decides which path should be taken based on several criteria. The decision criteria are as follows:
- IO latencies, queue depth and performance data per path
- As there are no longer any fixed selection modes, the plugin automatically adjusts which path should be used.
While SATP is responsible for managing and recognizing storage arrays, PSP (under NMP) or PSS (under HPP) handles the actual path selection and load distribution.
But what does the flow of the IO look like?
With the previous knowledge about the PSA and all plugins, we are now able to deduce how the IO gets from the ESXi to the storage. This results in the following process (for the NMP):
- a VM must make an IO request to the respective storage device. That storage device has an owner. For example: NMP
- NMP determines which PSP is assigned to the storage device where the IO should go.
- PSP now determines physical path for IO transfer.
- IO is transported via the path in the direction of storage
- if IO is transported cleanly to the storage –> Complete
- if IO is not transported cleanly to the storage –> Error –> NMP calls SATP
- SATP interprets the error and activates inactive paths
- PSP selects a new path into the storage
How do I check the settings on one of my storage devices?
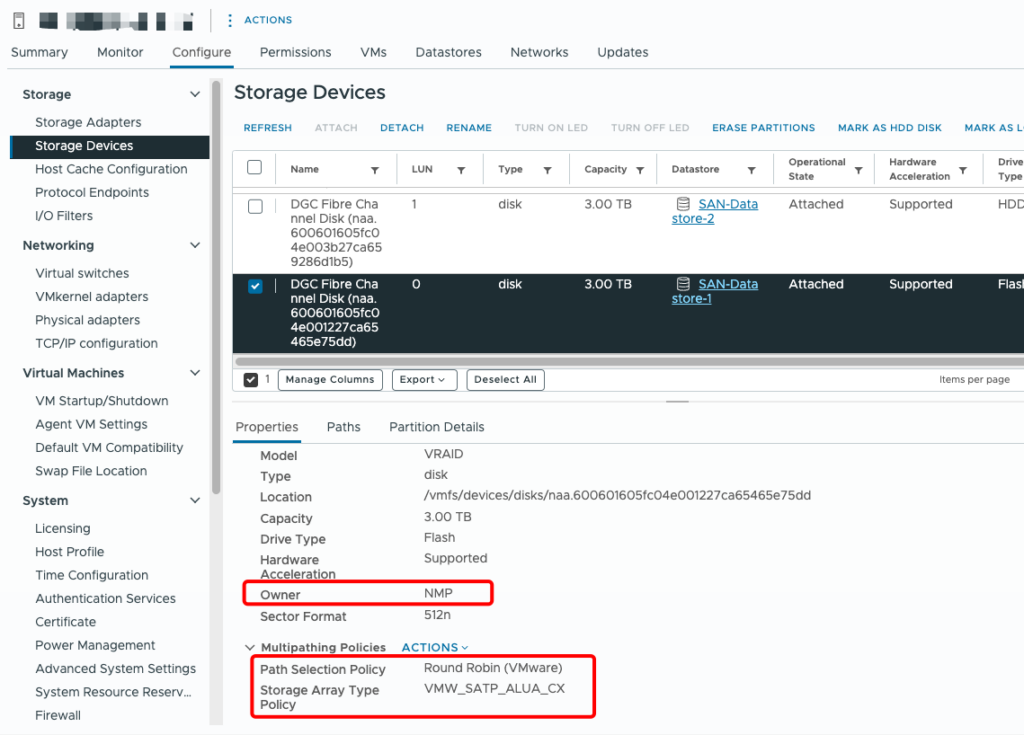
Here is a screenshot from the lab at work. We can see that the respective LUN is managed by NMP. Round Robin is selected as the path selection policy. This means that the IO is sent in rotation via all available paths. The SATP is set to ALUA_CX.
Conclusion
All processes are now largely automated and you have to do relatively little. And from an admnistratie perspective of view, the PSA is nothing that will help you with your daily admin tasks. Nor will you keep all the information from the post permanently in your head. The PSA in particular is full of abbreviations. I also had to dig deep into my books and read documentation from VMware for this blog post. However, in order to better understand how an ESXi “works”, I don’t think it’s wrong to have heard of the PSA. Personally, I found the preparation of this blog post exciting and I look forward to seeing you again next time. The next Deep Dive will be about host isolations in the context of HA. But that will take a while yet.
In the meantime, have a nice day and see you soon!


